Prompt Engineering完全指南:从提示工程到上下文工程的实战教程
AI 教程:Prompt Engineering
提示工程主要关注提示词的设计、优化与策略制定,致力于帮助用户更高效地调动大语言模型的能力,进而推动其在各类实际场景和研究领域中的应用。
1. 基础概念
1.1 什么是 Prompt Engineering
提示词就是:你通过自然语言的方式去告诉模型应该做什么,应该怎么做,什么能做,什么不能做,就这么简单。
1.2 提示词的必要格式
- 指令(Instruction):明确告诉模型需要它做什么
- 上下文(Context):相关的背景信息,让模型有更多的上下文用于决策
- 输入数据(Input Data):必要的输入,可以是问题、目标等
- 输出提示(Output Constraints):约束输出格式、风格或长度,让结果更符合你的需求
1.3 什么是 Context Engineering
上下文工程是一种为大语言模型构建、优化、动态管理输入上下文的工程化方法。主要包括:
- 信息收集和整合:从多源数据中获取与任务高度相关的内容
- 结构化和格式化:将信息结构化组织,按照一定格式提供给大模型
- 上下文管理:在有限的上下文窗口内,通过裁剪、隔离、压缩、持久化等手段来管理
- 工具和外部系统接入:通过与外部工具和系统交互,增强模型的能力
1.4 与操作系统的类比
大语言模型(LLM,Large Language Model)可以类比为新一代操作系统(OS,Operating System),其中上下文窗口(Context Window)相当于内存(RAM),而上下文工程则类似于操作系统中的调度器,负责将最关键的进程和数据装载到有限的内存空间中。
本质上,上下文工程是让大模型在特定场景下具备即插即用的任务能力。大模型在推理的时候所拥有的只有训练阶段获得的能力 + 上下文内容,在前者无法改变的情况之下,后者显得尤为重要。
核心洞察:不管大模型曾经执行或者交互过多少轮次,最新的这次只能依赖所提供的上下文去做推理,因此上下文在推理阶段才如此重要。
大语言模型需要上下文,错误源于信息不足,而不是模型不够好,复杂任务及多源信息融合的挑战。
训练和微调决定了模型的能力,上下文工程则决定了模型能发挥出多少能力。
2. Prompt Engineering 与 Context Engineering 对比
2.1 Prompt Engineering
是用一句话、一段话、一个格式、一个 role prompt 来激发模型的潜力。
特点:
- 静态、单轮、指令导向
- 适用于封闭任务、结构化回答
- 零样本提示/少样本提示/思维链提示 等技巧层出不穷
2.2 Context Engineering
在运行时持续的获取相关的信息,基于这些信息做出最佳的决策,产生最合适的结果。
特点:
- 动态、多轮、环境导向
- 支持状态管理、任务演进、链式推理
- 具备 Agent 级别的操作能力
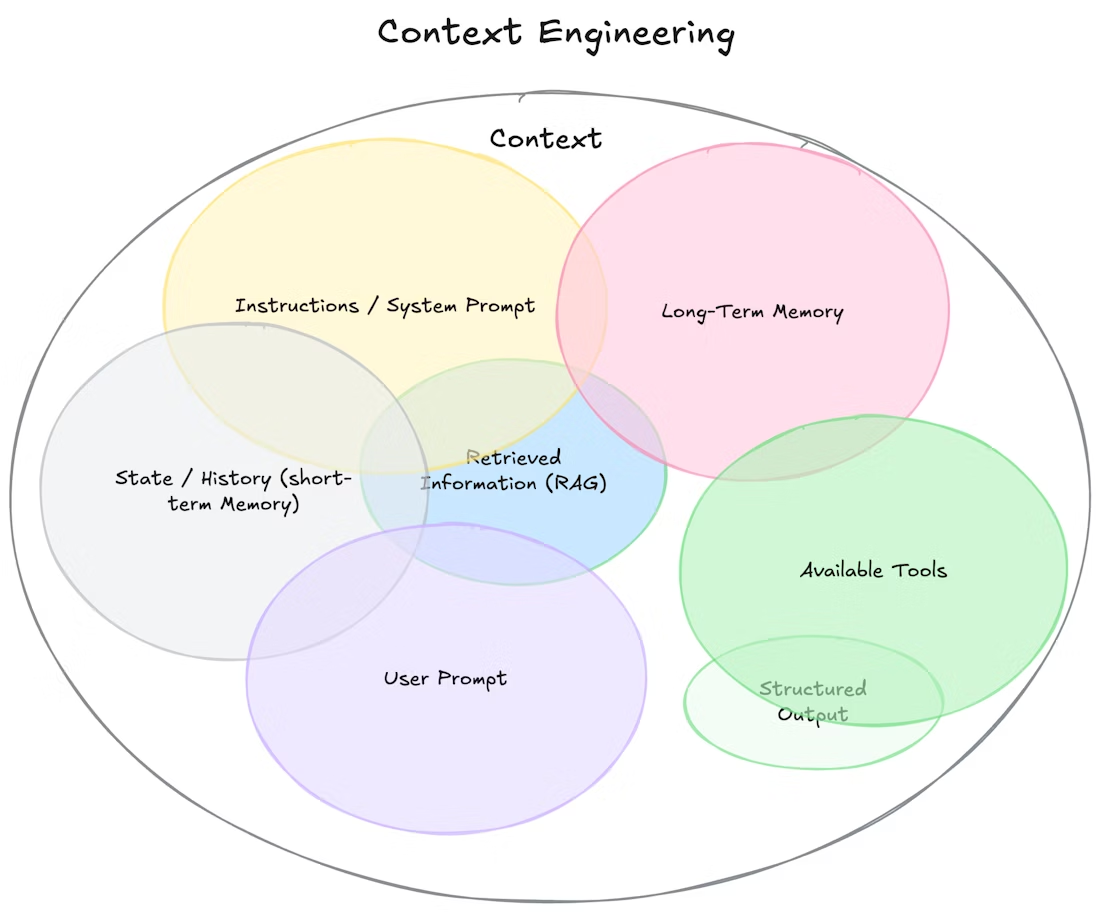
上下文工程维恩图
这张图用较为直观的方式展示了上下文工程中,目前涉及的一些技术手段
3. 上下文工程面临的挑战
3.1 上下文长度限制
传入太少,信息不足,无法推理出好的结果;传入太多,模型注意力分散,无法聚焦。上下文工程就是制造合适的上下文供模型使用推理。
3.2 污染问题(Poisoning)
错误信息持续留在上下文中,造成重复错误行为、目标偏离和行为死循环。
问题描述: 在上下文过长的情况之下,因为一些错误或者不合适的信息混杂在上下文中并且一直持续存在于上下文中,导致 Agent 可能不断重复做出错误的决策或举动。
重要提醒: 更大的上下文不一定是最好的选择,还是要取决于具体的使用场景和上下文工程策略来决定,因此不要盲目追求大上下文窗口和超长上下文的组装,那样有可能让结果恶化。
典型示例: 大模型擅长模仿,当他审阅简历时,如果之前 20 份都是不通过,即使下一份简历不错,大模型也可能会模仿之前的操作,给予简历不通过。大模型倾向于模仿,因此如果提供的样本是规律重复的,就会导致模型倾向于模仿样本,导致后续的行为不断重复。
解决方案: 引入更多的多样性。通过在动作和观察中加入少量有结构的变化来实现这一点——比如使用不同的序列化模板、替换措辞、在顺序或格式上加入细微扰动。这种"可控的随机性"有助于打破固定模式,重新调整模型的注意力焦点。
经验总结: 别让 few-shot 提示把你困在一种套路里。上下文越单一、越一致,你的智能体就越脆弱。
核心原理: 无论是 LLM 陷入错误幻觉与循环还是因为单一样本/少样本提示而产生重复行为,其本质都是上下文中充斥了不相干、误导性或错误信息,从而使大模型产生错误倾向的结果。这种错误倾向短期内无法被快速纠正,需要有检测和预防机制。
3.3 注意力偏移(Misalignment)
上下文长度增加会导致效果变差,其中的核心是上下文分心,模型被上下文分散了注意力,并且还会进一步让注意力从目标或指令转向无关的上下文。
问题表现:
- 过长的上下文
- 相似但无关的上下文
- 当上下文长度到达一定程度的时候,会导致模型过于专注于上下文,而忽略了在训练时获得的知识
- 上下文过长,模型无法专注于指令(instruction)
解决方案: 每次都更新 todo list,锁定大模型的注意力,将最新的 todo list 放在最后,效果更好。
3.4 语义冲突与混乱(Semantic Conflict & Confusion)
上下文存在歧义、矛盾或冗余等情况,导致模型难以理解和识别,导致最终效果不符合预期。
问题原因: 新引入的信息或工具与已有上下文中的内容产生矛盾,导致模型产生困惑、做出错误判断,甚至出现"随机选择"的不稳定行为。
典型示例:
- 多轮交互问题: 将单轮次的交互拆成多轮次,会导致模型的效果显著下降。每次模型接收到的信息都是局部的,不够完整,模型在早期做出了不完整甚至是错误的回答,这些错误信息会持续留在上下文中,并在最终生成答案时影响模型判断。
- 工具冲突: 如果挂载过多的工具,无论是内置还是 MCP,可能会出现相似描述导致模型不知道选择哪个,最终结果就是在相似的工具里进行非确定性选择(或可称为随机选择),导致生成结果不稳定甚至错误。
对比优势: 单轮直接给予全量信息,则可以让大模型产生更少的错误信息。
4. 上下文工程技术体系
4.1 上下文增强(Context Augmentation)
主要目的: 补充信息
技术手段:
- prompt:提示词技术
- RAG:检索增强生成
- tools:工具调用(FunctionCall, MCP, skills)
4.2 上下文优化(Context Optimization)
主要目的: 清洗和优化上下文
上下文隔离
- 拆分无状态任务:给 sub agent 执行,sub agent 就是独立的上下文
- 记忆系统:通过长期记忆与短期记忆隔离管理,在需要时引入
- 专业上下文:为专业任务配置专属上下文,如医疗、法律、编程等
上下文压缩
- 提取式摘要(Extractive Summarization):直接选出原文中最相关的段落、句子
- 抽象式摘要(Abstractive Summarization):用自己的话总结信息,常结合 LLM 实现
- 结构化摘要(Structured Summarization):提取出知识点、任务、目标等结构化信息,如 To-do 列表、决策路径
- 自我总结(Self-summarization):模型每一轮对话之后,自动总结这轮信息并作为输入传递,形成压缩上下文链
- 摘要记忆(Summarized Memory):结合记忆机制,将历史摘要作为长期记忆引用
- 时间窗口裁剪(Time-based Pruning):仅保留最近或关键时段的上下文,剔除历史冗余信息,提升推理精度
4.3 上下文持久化(Context Persistence)
主要目的: 保留信息
实现方式: 涉及一些外部记忆模块的持久化服务,使用文件系统/数据库。
5. 实战建议与最佳实践
- 平衡上下文长度:根据具体任务选择合适的上下文大小,避免过长或过短
- 预防上下文污染:定期清理和更新上下文,引入多样性防止模式固化
- 管理注意力焦点:使用 todo list 等工具锁定模型注意力
- 避免语义冲突:确保上下文信息的一致性和逻辑性
- 选择合适的技术组合:根据场景灵活运用增强、优化和持久化技术
📚 延伸阅读
🔗 AI 大模型系统教程系列
- AI 大模型完全指南 - 从零基础到 Token 与向量的深度解析
- Transformer 架构深度解析 - 注意力机制与 AI 大模型的核心技术
- [本文] Prompt Engineering 完全指南 - 从提示工程到上下文工程的实战教程
- AI 专业名词解释表 - 270+术语完全指南与 AI 技术体系词典
🎯 实践建议
- 理论结合:先掌握 AI 大模型基础概念,再学习本文的实战技巧
- 架构理解:深入理解 Transformer 架构有助于优化 Prompt 设计
- 术语参考:开发过程中遇到专业术语时,随时查阅 AI 专业名词解释表